前言
记得前文《回溯》中作者承诺要在后面优化回溯算法,果然这一章好几个都是前面的例子。以前我做过一些动态规划的题目,却总是不得要领。通过“递归->回溯->动态规划”这样循序渐进的讲解,现在我真是醍醐灌顶啊!
知识点
斐波那契数列
计算斐波那契数列是一个老生常谈的问题了,下面给出较为常见的算法伪代码:
其实这种单纯的递归算法是相当慢的。抛开递归调用不看,整个算法只有一个常数级的步骤:一次比较或者一次加法。如果用T(n)表示RecFibo,递推式如下:
这个看起来有点像是斐波那契的通项公式啊!写出T(n)的前几项值来看,T(n)可以化简为$T(n)=2F_{n+1}-1$,可以通过归纳法验证。通过一些超出本书范围的方法可知$F_n=\Theta(\phi^n)$,$\phi=(\sqrt5+1)/2≈1.61803$(黄金分割比例)。简单来说,这个递归算法的运行时是指数级别的。
那怎么才能直接看出是不是指数级增长呢?如果把RecFibo的递归看成是一颗二叉树,它的叶子节点是0或者1。因为最终输出的是$F_n$,那就刚好需要有$F_n$个叶子节点的值是1;这些叶子节点代表RecFibo(1)的调用。由一次简单的归纳可知RecFibo(0)刚好调用了$F_{n-1}$次。(如果我们只要一个渐进边界,得知RecFib(0)的调用次数最多和RecFibo(1)一样就足够了)这样,整棵递归树有$F_n+F_{n-1}=F_{n+1}$个叶子节点,又因为它是一棵满二叉树(国内外的定义不一样),他总共有$2F_{n+1}-1=O(F_n)$个节点。
记忆化
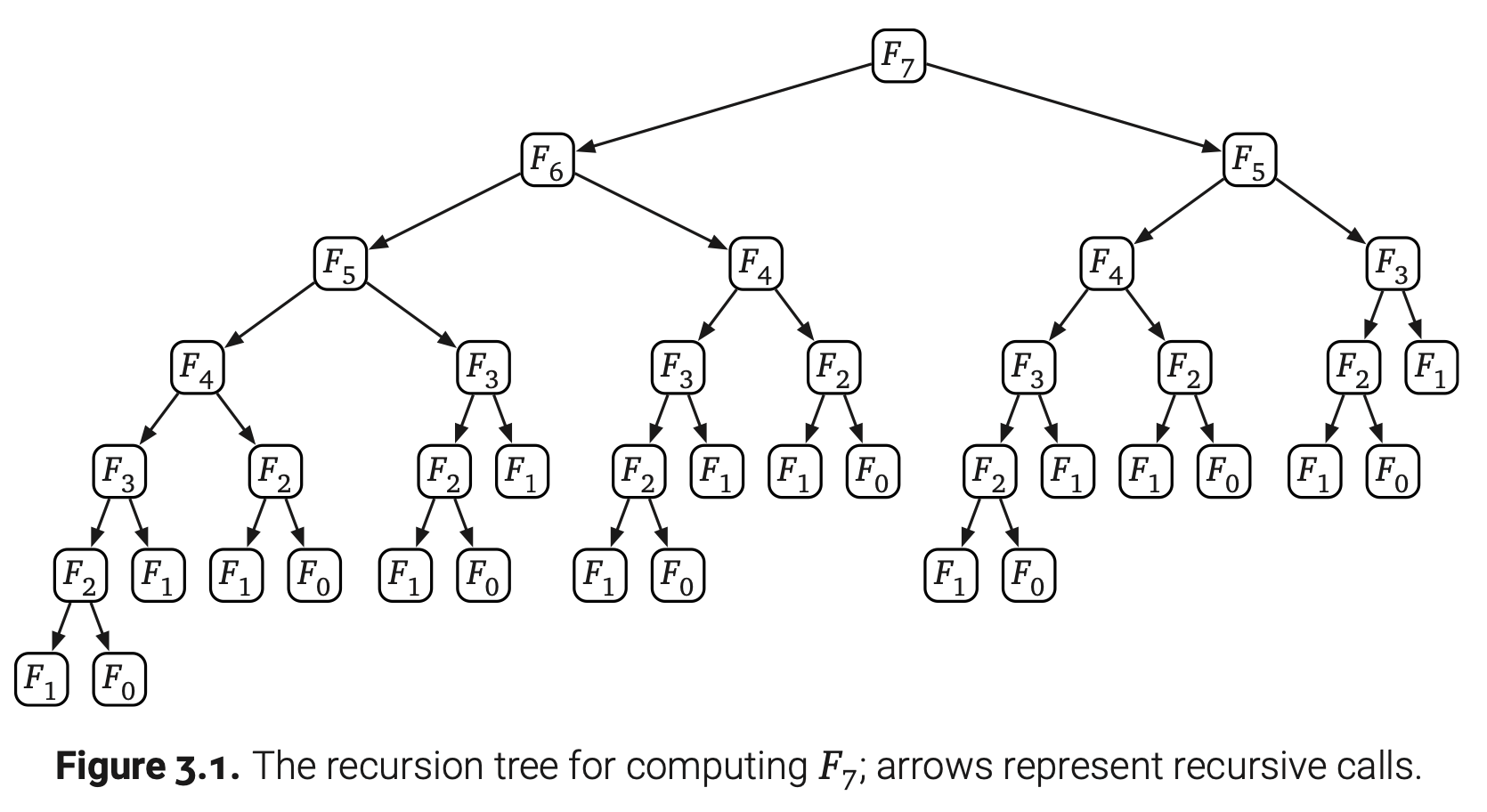
造成此算法运行慢的明显原因就是重复计算相同的斐波那契项。如果在第一次计算出某个中间项就记录下来,后面用到它的时候直接到记录中去查,这样就可以避免一些无意义的递归调用,从而加速算法的执行。最简单直接就是用数组来存中间项,优化过后的伪代码如下:
如果只考虑加法执行的次数,又因为每个斐波那契项只计算一次,那么MemFibo的运行时就是$O(n)$。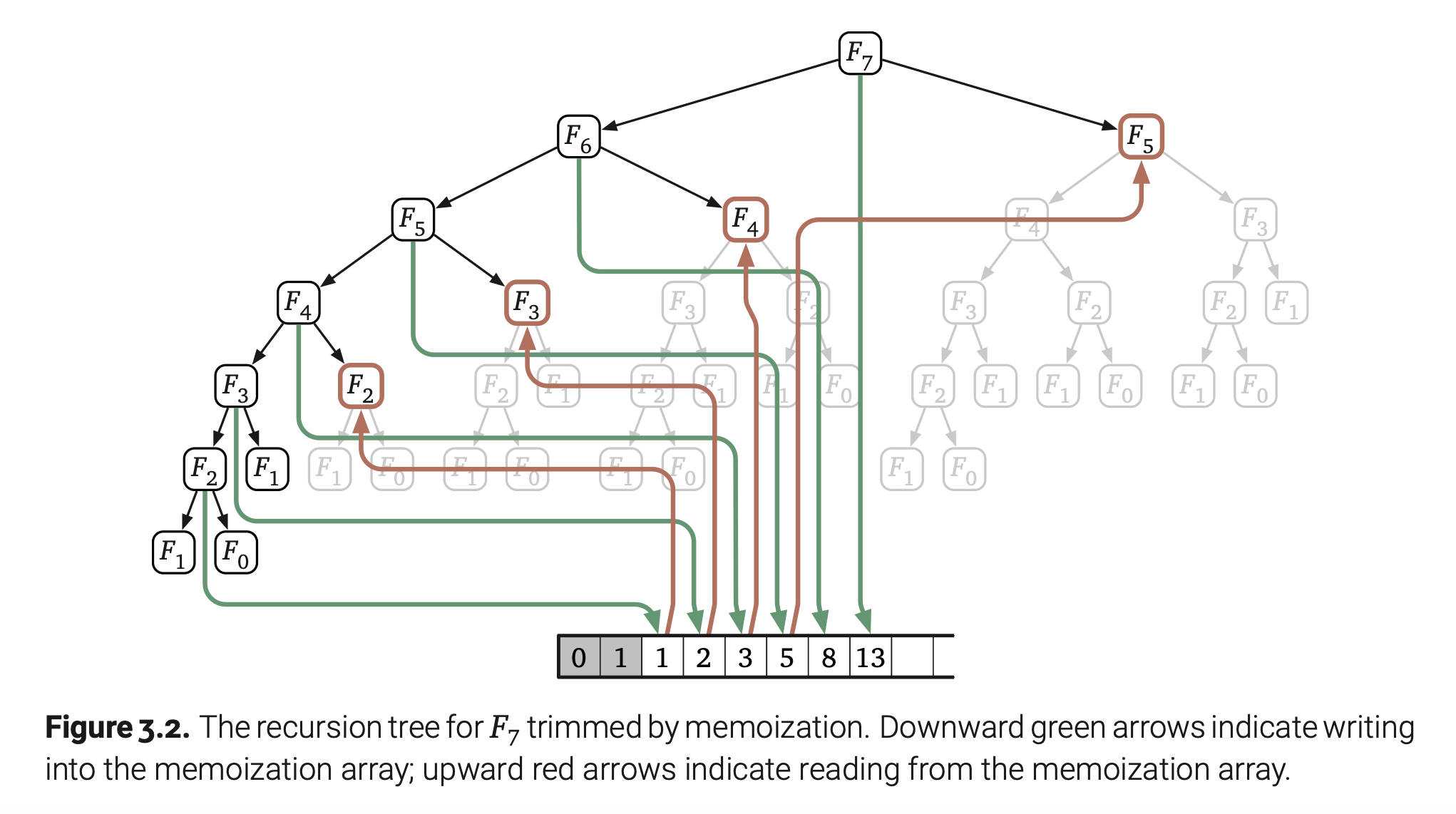
打表
一旦我们看出了F[]数组是怎么填充的,就可以使用for循环有意按顺序填充数组,而没有必要去依赖一个相对复杂的递归算法。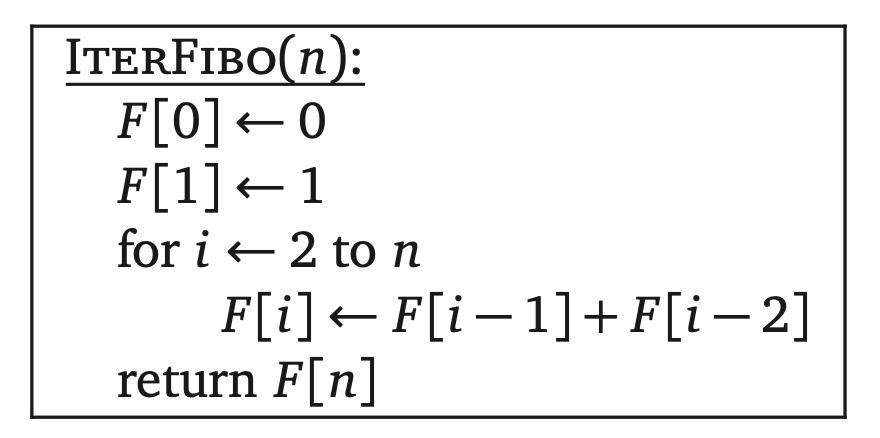
现在我们就可以清晰的看出:IterFibo使用$O(n)$次加法,存储了$O(n)$个整数。
存储关键信息
在许多动态规划算法中,没有必要保留计算过程中的所有结果。比如IterFibo算法就可以优化成只维持两个最新的数组元素。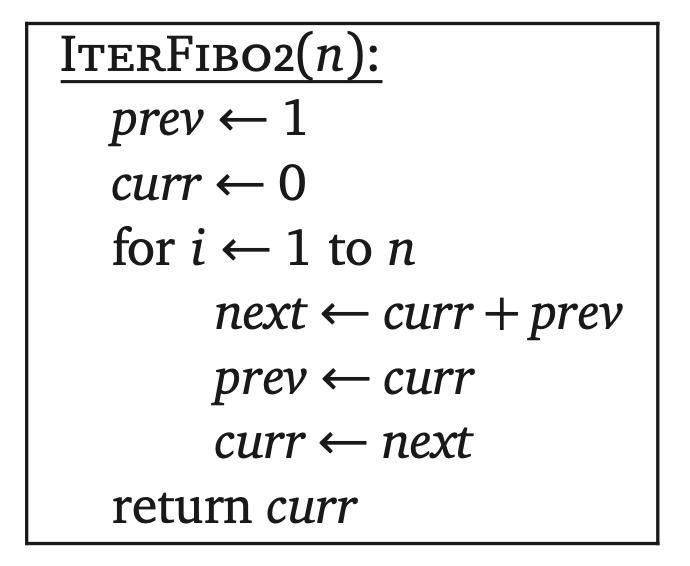
更快计算斐波那契数
尽管前一个方法看起来简单漂亮,但他还不是计算斐波那契数的最快算法。我们通过利用下面这个斐波那契的矩阵变形式得到一个更快的算法:
换句话说,一个二维矢量乘上矩阵$\begin{bmatrix} 0 & 1 \ 1 & 1 \end{bmatrix}$和IterFibo2中的单次循环迭代的效果是一样的。那么下面的矩阵乘上n次和循环迭代n次相同:
所以如果我们想要计算第n个斐波那契数,我们只需要计算出矩阵$\begin{bmatrix} 0 & 1 \ 1 & 1 \end{bmatrix}$的n次方。如果我们使用重复平方法来计算矩阵的n次方只需要$O(log n)$次乘法,这里的2X2的矩阵相乘可以降低为常数级别的乘法和加法,这样,我们可以通过$O(log n)$次整数算数运算计算出$F_n$。
我们同样可以通过这个递推式$F_n=F_mF_{n-m-1}+F_{m+1}F_{n-m}$来完成同样的优化加速,通过归纳法我们可以证明对于所有的整数m和n都是有效的。尤其是这个递推式可以推导出下面两个相邻斐波那契数的递推式:
根据这连个递推式可以写出如下算法:
通过我们标准的递归树技术可以看出这个算法只需要执行$O(log n)$次整数算数运算。
并没有多快
斐波那契数的增长是指数级别的。第n个斐波那契数的长度大约是$n log_{10}\phi≈n/5$位十进制数,或者$n log_2\phi$位二进制数。那么我们不能在对数级时间内计算出$F_n$。
问题的关键就是我们不能再常数时间内计执行任意精确地算术。用$M(n)$表示计算两个n位数相乘的时间。FastRecFibo的运行时递推式就是$T(n)=T(\lfloor n/2\rfloor)+M(n)$,这里通过递归树解出来得到$T(n)=O(M(n))$。目前已知最快的整数乘法运行时是$O(n log n)$,那么这也是FastRecFibo的运行时。
那么这个算法的运行时回避线性迭代算法慢吗?事实上,任意两个数的加法也不是常数级别的。两个n位数相加需要的运行时是$O(n)$,那么迭代算法IterFibo和IterFibo2的实际运行时间是$O(n^2)$。所以FastRecFibo明显还是比迭代算法快。
在最初的递归算法中,那些任意精确算术的消耗已经淹没在了海量的递归调用中了。
字符串分割优化
接下来的例子是上一章的字符串分割,已知一个字符串A[1..n]和一个判断是否为单词的子程序IsWord,我们想知道A能不能分割成一系列的单词。Splittable(i)返回true表示后缀A[i..n]可以分割为一系列单词,这个函数满足以下递推式:
这个递推式如果直接写成回溯算法,在最坏情况下会调用$O(2^n)$次IsWord方法。
但是对于任何确定的字符串A[1..n],最多只有n种不同的方式去调用Splittable(i)—$1\leq i\leq n+1$—而且只有$O(n^2)$种不同的方式去调用IsWord—$1\leq i\leq j\leq n$。那么为什么我们会使用指数级的时间来计算多项式级数量的东西呢?
每次递归子问题都会指定一个1到n+1之间的整数,那么我们把Splittable函数的结果记录到SplitTable[1..n+1]数组中。每一个子问题Splittable(i)又依赖于子问题Splittable(j),j>i,那么记忆化递归算法应该按照索引从大到小的顺序来填充数组。如果我们有意地填充数组,就能得到下面这个动态规划算法,它执行IsWord的次数为$O(n^2)$。
模式
简单地说,动态规划就是没有重复的递归。动态规划会存储中间子问题的结果,通常但不总是以数组或者表的形式。很多人都会错误地致力于怎么实现记忆化而不重视如何找到一个正确的递推式。只要我们找到了正确的递推式,那么再谈如何去记忆化就很明显了,但是如果递推式是错误的,任凭你再怎么优化也是徒劳的。
动态规划算法最好划分为两个阶段来实现。
1.递归地描述问题。将整个问题划分为一些子问题并且为之写下一段递归公式或者算法。这是非常困难的一步,一个完整的递归表述有两个部分:
(a)详细描述。用连贯清晰的语言描述一个你想要递归解决的问题—并不是如何去解决问题,而是你要解决的问题是什么。如果没有详细描述,根本就没办来判定你的答案是否正确。
(b)解决方案。为整个问题给出一个清晰的递归描述或者算法,其中又包含一些范围较小却又正好与原问题相同的子问题。
2.自下而上的解决递推式。通过正确顺序地考虑中间子问题,以递推式的基础边界情况开始向上递推写出一个算法。这个阶段可以分解成几个较小且相似的机械化步骤:
(a)确定子问题。给你一个初始输入,你的递归算法可以通过多少种不同的方式调用自身?例如,RecFibo的参数总是0到n之间的整数。
(b)选择一个存储数据结构。找到一个可以存储每一个确定子问题结果的数据结构。我们通常但不总是使用多为数组。
(c)确定依赖关系。除了基础边界情况,每一个子问题都会依赖其他的子问题。为你的数据结构画一幅图,选择一个一般性的元素,画出它所依赖的其他元素。
(d)找到一个正确的求值顺序。对相互依赖的子问题排序。首先考虑基础边界情况,最后构造出最原始最上层的问题。你上一步确定的依赖关系将会用来确定上层的子问题部分情况;你需要找到这些部分情况的线性扩展。
(e)分析空间和运行时。不同子问题的数量决定了记忆化算法的空间复杂度。为了计算总共的运行时,累加所有可能子问题的运行时,假设更深层粗的递归调用已经被记录了。这个一步也可以在(a)之后直接进行。
(f)写下算法。你知道该通过什么顺序来考虑子问题,也知道怎么解决每个子问题。如果你的数据结构是一个数组,这就意味着你可以写一个嵌套循环来代替递归调用。
别用贪心算法
这一小节作者就是在喷使用贪心有多愚蠢!任何可以用贪心算法解决的问题都可以用动态规划解决。我就留个标题作个提醒吧!
最长递增子序列优化
第一个递推式
又是一个上一章的例子。给你一个数组A[1..n],LISbigger(i,j)表示A[j..n]中元素值比A[i]大的最长递增子序列。下面是递推式:
为了解决原始问题,我们需要增加一个哨兵值A[0]=-∞到数组中,然后计算LISbigger(0,1)。
每一个递归子问题都定义了两个索引i和j,所以总共只有$O(n^2)$个不同的递归子问题。我们可以使用一个二维数组LISbigger[0..n,1..n]来记录这些子问题。不算递归调用次数,每个子问题可以在$O(1)$时间内解决。所以我们可以预测最后的动态规划算法执行时间应该是$O(n^2)$。
这里填充记忆数组的顺序并不是十分清晰;我们仅仅知道LISbigger[i,j]填充的时机应该在LISbigger[i,j+1]和LISbigger[j,j+1]之后。就像下面这张图: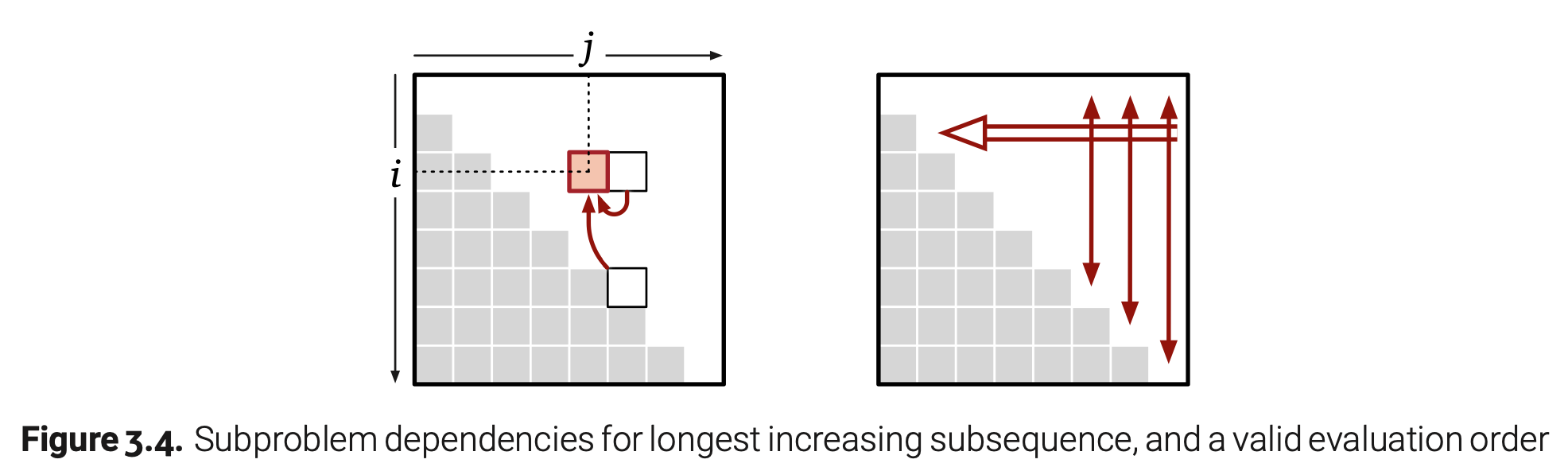
幸运的是这一信息已经足够给我们一个有效求值的顺序。如果我们从右到左一次填充一列数据,那我们计算当前一个数据时,前一列的数据都是可用的。这也许不是递归算法所使用的的顺序,但它确实有效的。上图阐释了这个求值顺序,双线箭头表示外层循环,单线箭头表示内层循环。因为我们填充每一行的顺序是不重要的,所以这里的单线箭头是双向的。
接着看看我们的伪代码;正如我们所预料的,这个算法的运行时就是$O(n^2)$。如果有必要,通过只维持最新的两列数据LISbigger[·,j]和LISbigger[·,j+1],我们可以我们可以空间大小从$O(n^2)$缩减到$O(n)$。
第二个递推式
我们第二个回溯算法来自于函数LISfirst(i),它表示以A[i]开头求A[i..n]的最长递增子序列。从这个定义我们可以得出以下递推式:
这里我们假设$\max ∅ = 0$,那么自然就可以知道LISfirst(n)=1。为了解决原问题,我们可以添加一个哨兵值A[0]=-∞,再计算LISfirst(0)-1。
现在我们的递归子问题只需要用到一个索引,所以我们也只需要一个一位数组LISfirst[1..n]来记录中间结果。每次填充LISfirst[i]只要已知所有LISfirst[j],j>i,那么我们直接降序填充数组即可。这个动态规划算法的执行时间是$O(n^2)$,运行空间是$O(n)$。
编辑距离
两个字符串之间的编辑距离是指通过插入、删除和替换操作把一个字符串变形成另外一个的最少操作次数。比如,把字符串FOOD变为MONEY需要四次操作:
为了更形象化,我们可以两个字符串并排起来。第一个串中间的空格表示插入,第二个串中间的空格表示删除。同一列有两个不同的字符表示替换。那么如果没有相同字符的列就是需要操作的。
很明显我们不能再三次操作内把FOOD替换成MONEY,所以FOOD和MONEY的编辑距离是四次。一般而言我们不能简单地看出最少编辑次数。比如下面可以看出字符串ALGROITHM和ALTRUISTIC的编辑次数是6。那这是不是最少编辑次数呢?
递归结构
为了开发一个计算编辑距离的动态规划算法,我们首先需要递归地详细描述这个问题。我们前面的排列形式有一个很关键的最佳子结构属性。假设我们已知两个字符串的最短编辑距离的排列形式。如果我们移除最后一列,那么剩下的行就代表着剩余前缀的最短编辑距离。我们可以通过反证法证明这个观察结论:如果前面提到的前缀有最短的编辑步骤,把最后一列放回去就能得到原字符串的最短编辑步骤。一旦我们弄清楚最后一列发生了什么,通过归纳法即可得出剩下的最佳排列形式。
换句话说,这里的排列形式就是我们从右到左编辑操作的序列。解决编辑距离问题需要做一系列的决定,输出的每一列是怎么排的。在这一系列决定中间,我们已经把一个串的后缀和另一个串的后缀排列好了。
因为已经决定部分编辑操作的次数正好是不匹配列的数量,剩下的决定并不依赖于我们已经决定部分的操作次数;它们只依赖于还未排列的前缀部分。
这样,对于任何两个字符串A[1..m]和B[1..n],我们可以将编辑距离问题递归表述为:对于任意i和j,用Edit(i,j)表示前缀A[1..i]和B[1..j]的编辑距离。我们需要计算出Edit(m,n)。
递推式
当i和j都是正数,如果要得到A[1..i]和A[1..j]的最短编辑距离,就需要考虑最后一列的三种处理方式:
•插入:第一个串最后一列为空,这种情况编辑距离就等于Edit(i,j-1)+1。后面的+1表示最后一列的操作是插入,剩下的部分再递归求解。
•删除:第二个串最后一列为空,这种情况编辑距离就等于Edit(i-1,j)+1。后面的+1表示最后一列的操作是删除,剩余的部分继续递归。
•替换:两个串最后一列都有字符。如果这两个字符不同,那么编辑距离就等于Edit(i-1,j-1)+1。如果这两个字符相同,这次替换就是免费的,编辑距离就等于Edit(i-1,j-1)。
这种一般情况的分析直到i=0或者j=0结束,但是这种边界情况很容易直接处理。
•把一个空串变成长度为j的串需要j次插入,Edit(0,j)=j。
•把一个长度为i的串变为空串需要i次删除,Edit(i,0)=i。
当然空串变为空串不需要任何操作。我们可以得出Edit函数满足递推式:
动态规划
现在有了递推式,根据下面机械化的流程我们可以直接将它转化为动态规划算法。
•子问题:每个子问题都有两个索引来定义,$0\leq i\leq m$和$0\leq j\leq n$。
•存储结构:要记录所有Edit(i,j)可能的值,需要一个二维数组Edit[0..n,0..n]。
•依赖关系:当我们计算Edit[i,j]的时候,他只依赖于三个相邻的元素,Edit[i-1,j]、Edit[i,j-1]、Edit[i-1,j-1]。
•求值顺序:按照从左到右,从上到下即可保证计算当前元素前他所依赖的三个元素已经有值了。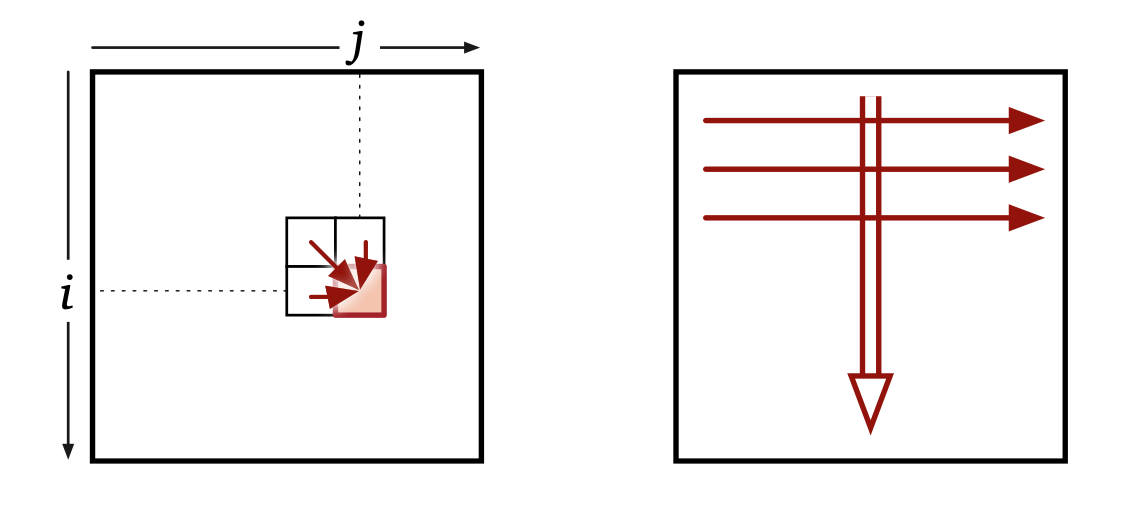
•空间和时间:存储结构的大小是O(mn),每次计算Edit[i,j]只需要O(1)的时间,所以该算法的运行时应该是O(mn)。
下面是最终的动态规划算法伪代码:
关于字符串ALGORITHM和ALTRUISTIC存储表的变化情况如下图。粗体数字表示所在位置的两个字符相同。字符串ALGORITHM和ALTRUISTIC的编辑距离确实是6。
图中的箭头表示每次填充的取值来源。每一个箭头方向对应着不同的编辑操作,垂直=删除,水平=插入,对角=替换。粗体红色的对角箭头表示相同字符免费替换。任何一条从左上到右下的路径都表示一个字符串之间的最佳编辑顺序。在图中我们可以找到三条这样的路径,每一条都表示字符串ALGORITHM变形为ALTRUISTIC的不同方式。
我们的编辑距离算法并没有实际去计算或者存储这些表中的箭头,但是我们可以通过这些表中的数值反向推出路径。只要我们填充完存储表,我们就可以在O(m+n)的时间内计算出最短的编辑顺序。
子集和优化
双是一个上一章的例子。已知一个正整数的数组X[1..n],问能不能找到X的子集,其所有元素之和为T?用SS(i,t)表示X[i..n]中有没有子集的和为t,递推式如下:
通过下面的模板,我们可以把这个递推式转化成动态规划算法。
•子问题:每个子问题都需要两个索引来表示,$1\leq i\leq n+1$和$t\leq T$。然而t<0的种情况是不重要的,所以没必要存储他们。我们可以将递推式改进如下:
•数据结构:只需要一个二维数组S[1..n+1,0..T],S[i,t]就表示SS(i,t)的结果。
•求值顺序:如果当前计算S[i,t],那么它只依赖于后面一列SS[i+1,·]的值。所以填充数组时外层循环需要从后往前,内层循环则不考虑顺序。
•空间和时间:前面定下的存储结构需要空间大小为O(nT),如果S[i+1,t]和S[i+1,t-X[i]]都是已知,那么计算S[i,t]只需要常数级的时间,整个算法的运行时也只需要O(nT)。
下面就是动态规划算法伪代码:
通常情况下动态规划算法都是优于递归回溯算法的。但也有例外,如果T大于了$2^n$,那么整个迭代算法就会比单纯的递归算法慢,因为它会去浪费大部分的时间去计算递归算法不会考虑的情况。
最佳二叉搜索树优化
叒是一个上一章的例子,输入一个已排序的数组A[1..n]和一个频率数组f[1..n],f[i]表示A[i]被访问的次数。用OptCost(i,k)表示子数组A[i..k]的通过最佳二叉树访问所有元素的时间,有如下递推式:
这个递推式里面的求和部分看起来不舒服,我们做一些调整。对于任意一对索引$i\leq k$,用F(i,k)表示A[i..k]的所有元素的直接访问次数:
这个方程满足递推式:
我们可以在$O(n^2)$时间内计算出所有可能的F(i,k),前提是使用动态规划算法。通过模板流程写出下面的算法: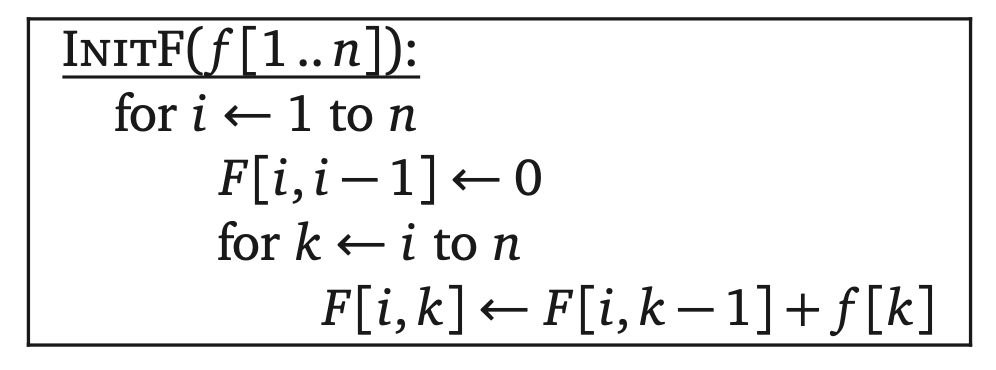
有了这个初始化方法,我们就可以原来的OptCost递推式简化如下:
接着按照正常流程来走。
•子问题:每个递归子问题的范围有两个索引决定,$1\leq i\leq n$和$0\leq k\leq n$。
•记忆化:使用一个二维数组OptCost[1..n+1,0..n]。
•依赖关系:OptCost[i,k]的计算依赖于OptCost[i,j-1]和OptCost[j+1,k],$i\leq j\leq k$。换而言之,每次填充的位置依赖于同列下侧或者同行左侧的值。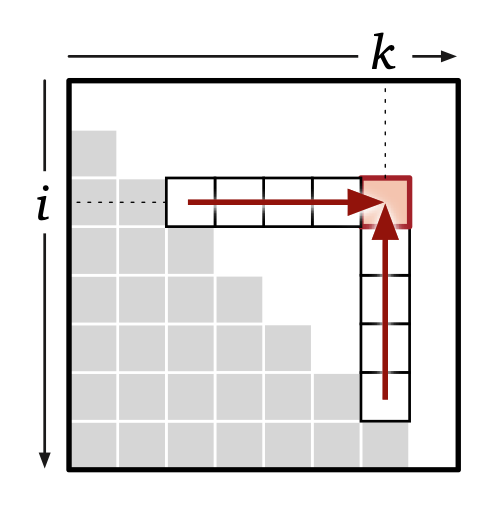
用下面的子程序来更新Opt[i,k],但前提是要保证依赖部分必须有值。
•求值顺序:这里有三种求值顺序,第一种把所有边界情况OptCost[i,i-1]都赋值,再去计算OptCost[i,i+d],d的值按顺序从0递增到n-1。最后就可以计算出OptCost[1,n]。
另外两种直接针对嵌套循环来说,他们分别是外层自底向上内层自左向右或者外层自左向右内层自底向上。
之前也说过,双线箭头表示外层循环,单线箭头表示内层循环。双向单线箭头则表示内存循环的计算顺序不重要。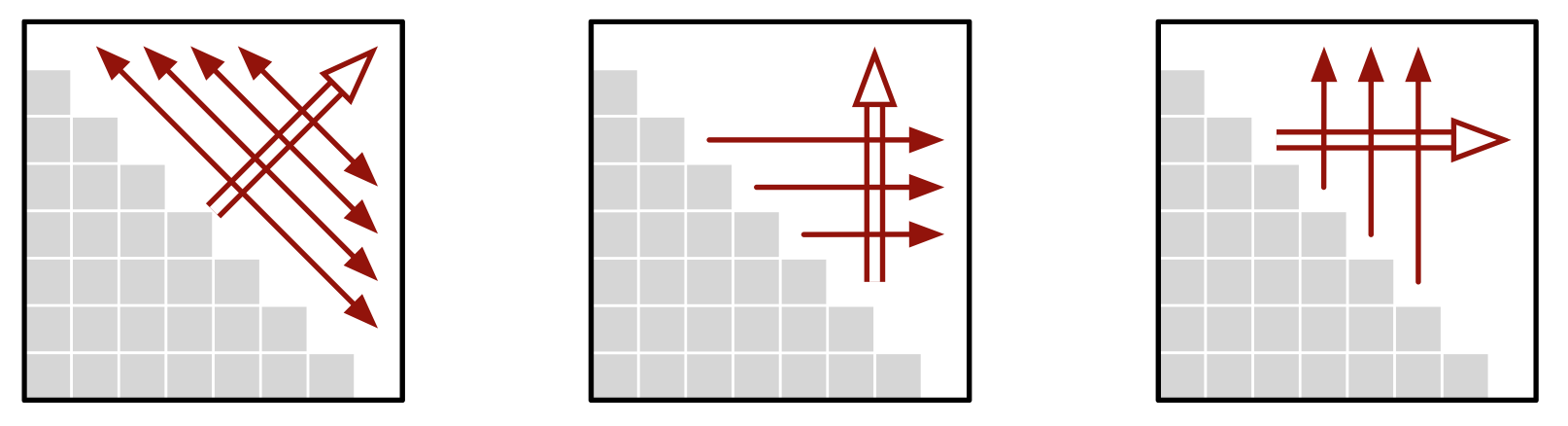
•空间和时间:存储空间大小为$O(n^2)$,不管使用的是那个求值顺序,我们计算Opt[i,k]需要的时间是O(n),所以整个算法需要的时间是$O(n^3)$。
通常我们可以直接从递推式中预测出空间和时间边界。OptCost函数有两个参数,每一个参数都有n个不同的值,所以我们大概知道数据结构的空间大小是$O(n^2)$。另外,递推式的右侧有三个变量i、k、r,每一个大概都有n个不同的值,所以要计算出所有情况应该需要$O(n^3)$的时间。
关于树的动态规划
到此,我们所有的动态规划例子都是用多维数组来存储递归子问题的结果。然而,接下来的这个例子将会告诉我们并不是所有情况都有适当的适当的数据结构可用。
一个图的独立集是它所有顶点的子集,其中这些点没有直接相连的边。找到任意一个图的最大独立集是极其困难的;事实上,这是一个权威的NP难问题,这个问题后面的章节会谈到。但是对于某些比较特殊的图,我们可以很快找到最大独立集。尤其是,输入的图是一个有n个顶点的树,我们可以在O(n)时间内找到最大独立集。
假设我们有一棵树T。为了不失普遍性,假设T是一棵有根的树;它就有一个特别的节点叫作根,所有的边都直接或者间接从这个点出发。(如果T是一棵无根树—一个非循环的连通无向图—我们可以选择任何一个点作为根)如果w通往根节点的唯一路径中包含v,那么我们就称w是v的后裔节点;同样的,v的后裔节点就包括它本身和它的子节点的后裔节点。以v作为根节点的子树就由v的所有后裔节点和它们之间的边构成。
对于任意T中的节点v,用MIS(v)表示以v作为根节点子树的最大独立集。在这个子树中任何不包括v的独立集都是以v的子节点作为根的子树的独立集组成的。另外,任意包括v的独立集都不包含v的子节点在内,因此他们包含的是以v的孙节点作为根的子树的独立集。这样,函数MIS遵守下面这个递推式,$w\downarrow v$表示w是v的子节点。
我们需要计算MIS(r),r是T的根节点。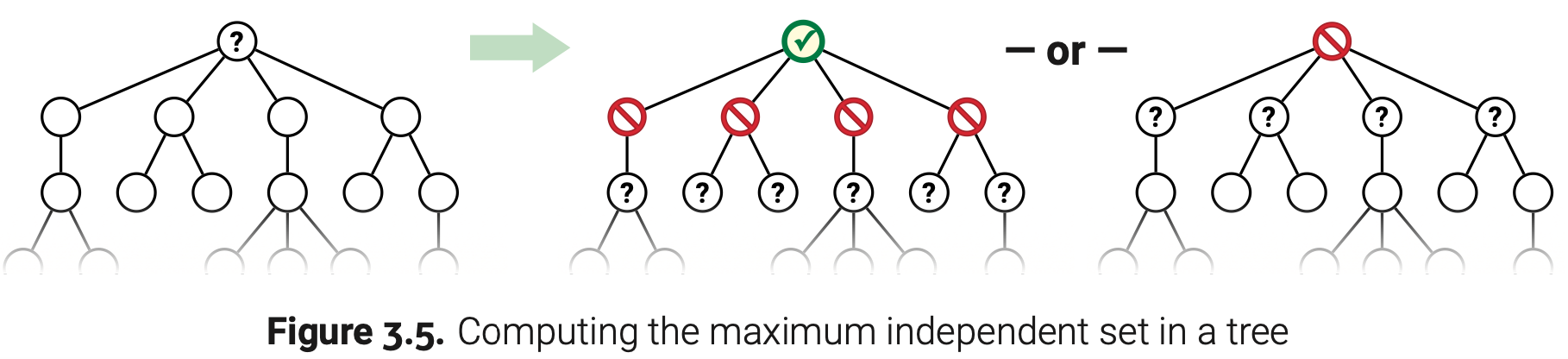
现在考虑我们该用什么数据结构来记录这个递推式呢?最自然的选择就是使用T本身!对于T中的每个节点v,给它构造一个新变量v.MIS来存储MIS(v)的结果。(原则上来说,我们还是可以使用数组,但是我们还需要知道每个节点的前驱和后继,显然数组就不太容易做到了)
怎么考虑子问题的顺序呢?如何解决关于v节点的子问题取决于关于v的子节点和孙节点的子问题。那么我们按任意顺序来访问节点,保证每个节点都在它的父节点之前被访问过了;特别是我们可以使用后序遍历。
这个算法的运行时怎么算呢?关于每个节点v的非递归运行时适合它的子节点和孙节点数量成比例的;这个数量肯定不是从一个点到另一个这么算。但是我们还是可以来分析一下:每一个顶点都为它的祖父节点和父节点贡献了常数级的时间!因为每个节点最多只有一个父节点和一个祖父节点,那么这个算法运行时间是O(n)。
下面就是动态规划算法。当然,他还是递归的,因为这是实现树的后序遍历的最常用的方法。
通过多定义两个函数,我们可以得出一个简单的线性算法。
•用MISyes(v)表示在以v为根节点的子树中包含v的最大独立集。
•用MISno(v)表示在以v为根节点的子树中不包含v的最大独立集。
根据定义有下面两个递推式:
关于存储结构只需要给每个节点定义两个新变量即可。直接后序遍历在O(n)时间内就可以计算出最大独立集。
在循环中的第二行,我们用到的w.MISno在前一行的递归调用中就已经计算出来了。
结语
我感觉每个例子都能加深我对动态规划算法的理解,所以这一篇我几乎是全文翻译了。特别是作者提出的动态规划问题的分析模式,它应该是本文的重中之重了。这套模式用在动态规划问题上简直屡试不爽,当然这只是我看了作者分析之后的感受。最后我建议不要一看是动态规划问题就拿这个模式往上套,因为作者说了“First make it work, then make it fast”。
原文链接
http://jeffe.cs.illinois.edu/teaching/algorithms/book/03-dynprog.pdf